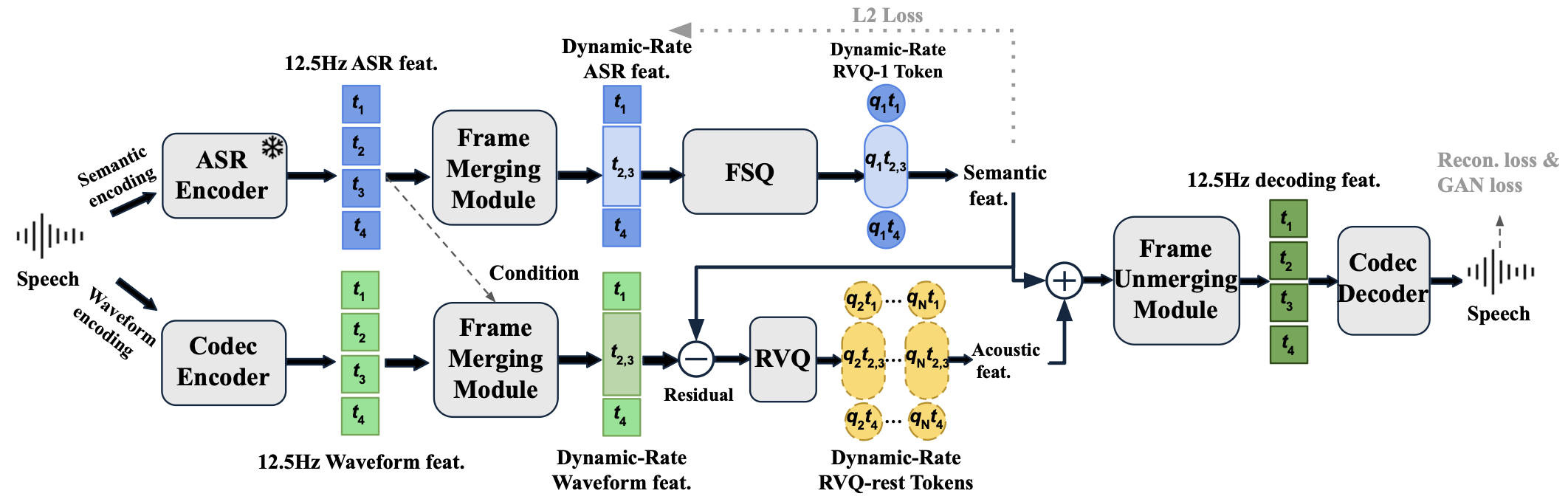
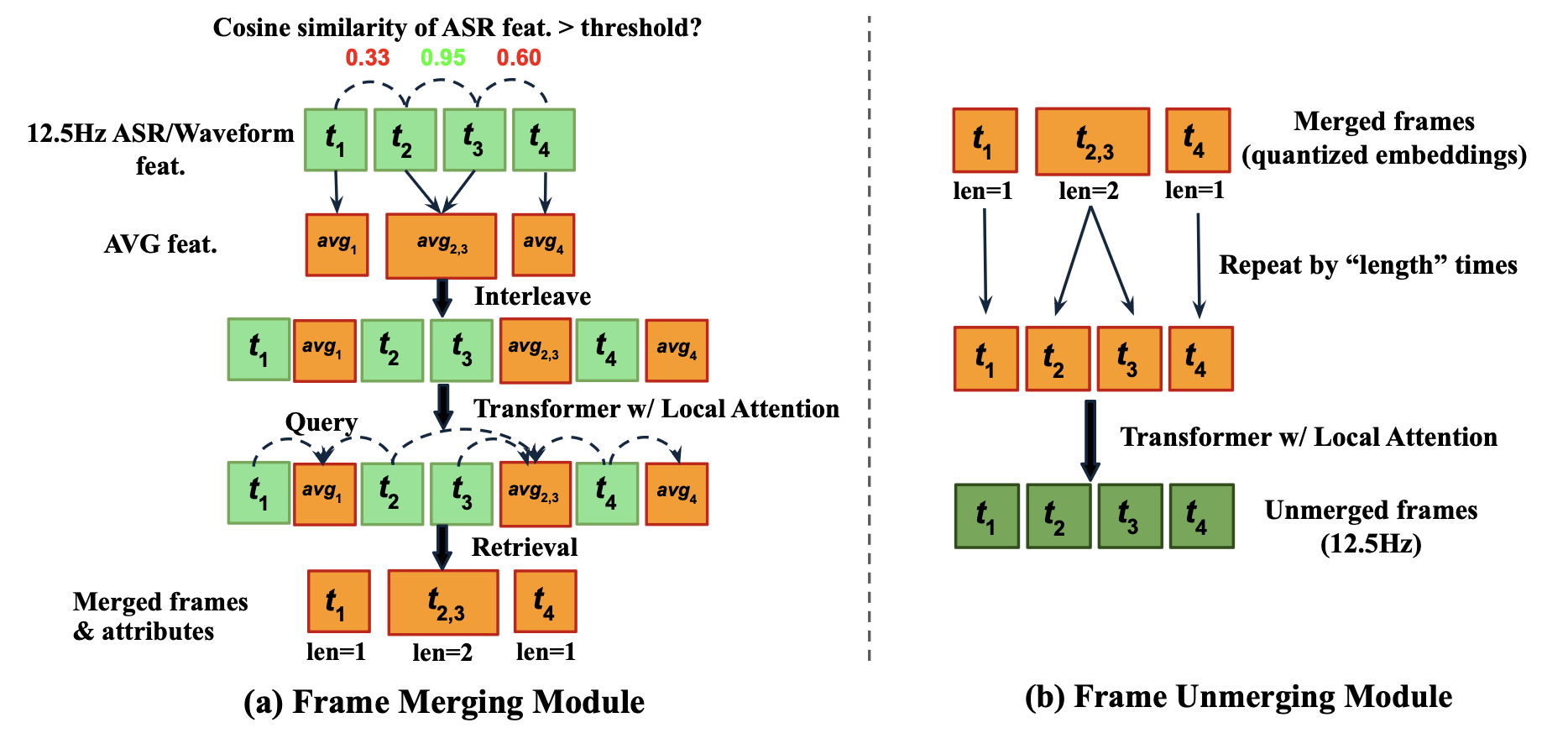
Neural audio codecs are foundational to speech language models. It is expected to have a low frame rate and decoupled semantic and acoustic information. A lower frame rate codec can reduce the computational cost of speech language models by shortening the sequence length. Recent studies have developed 12.5Hz low-frame-rate audio codecs, but even lower frame rate codecs remain underexplored. We find that a major challenge for very low frame rate tokens is missing semantic information. This paper introduces FlexiCodec to address this limitation. FlexiCodec improves semantic preservation with a dynamic frame rate approach and introduces a novel architecture featuring an ASR feature-assisted dual stream encoding and Transformer bottlenecks. With dynamic frame rates, it uses less frames at information-sparse regions through adaptively merging semantically similar frames. A dynamic frame rate also allows FlexiCodec to support inference-time controllable frame rates between 3Hz and 12.5Hz. Experiments on 6.25Hz, 8.3Hz and 12.5Hz average frame rates confirm that FlexiCodec excels over baseline systems in semantic information preservation and delivers a high audio reconstruction quality. We also validate the effectiveness of FlexiCodec in language model-based TTS.
| Method | Frame Rate (Hz) | Dynamic Rate | Controllable Rate | Semantic Augmentation | Has TTS Results? |
|---|---|---|---|---|---|
| DAC | 75 | ✗ | ✗ | ✗ | ✗ |
| SpeechTokenizer | 50 | ✗ | ✗ | SSL feature (HuBERT) | ✓ |
| CodecSlime | 40 (Avg) | ✓ | ✓ (40,50,67,80Hz options) | ✗ | ✗ |
| Mimi | 12.5 | ✗ | ✗ | SSL feature (WavLM) | ✓ |
| DualCodec | 12.5/25 | ✗ | ✗ | SSL feature (w2v-bert-2) | ✓ |
| TaDiCodec | 6.25 | ✗ | ✗ | Text | ✓ |
| Phoneme Tokens | 11.7 (Avg) | ✓ | ✗ | - | - |
| BPE Text Tokens | 4.5 (Avg) | ✓ | ✗ | - | - |
| FlexiCodec | 6.25/8.3/12.5 (Avg) | ✓ | ✓ (Any from 3 to 12.5Hz) | ASR feature | ✓ |
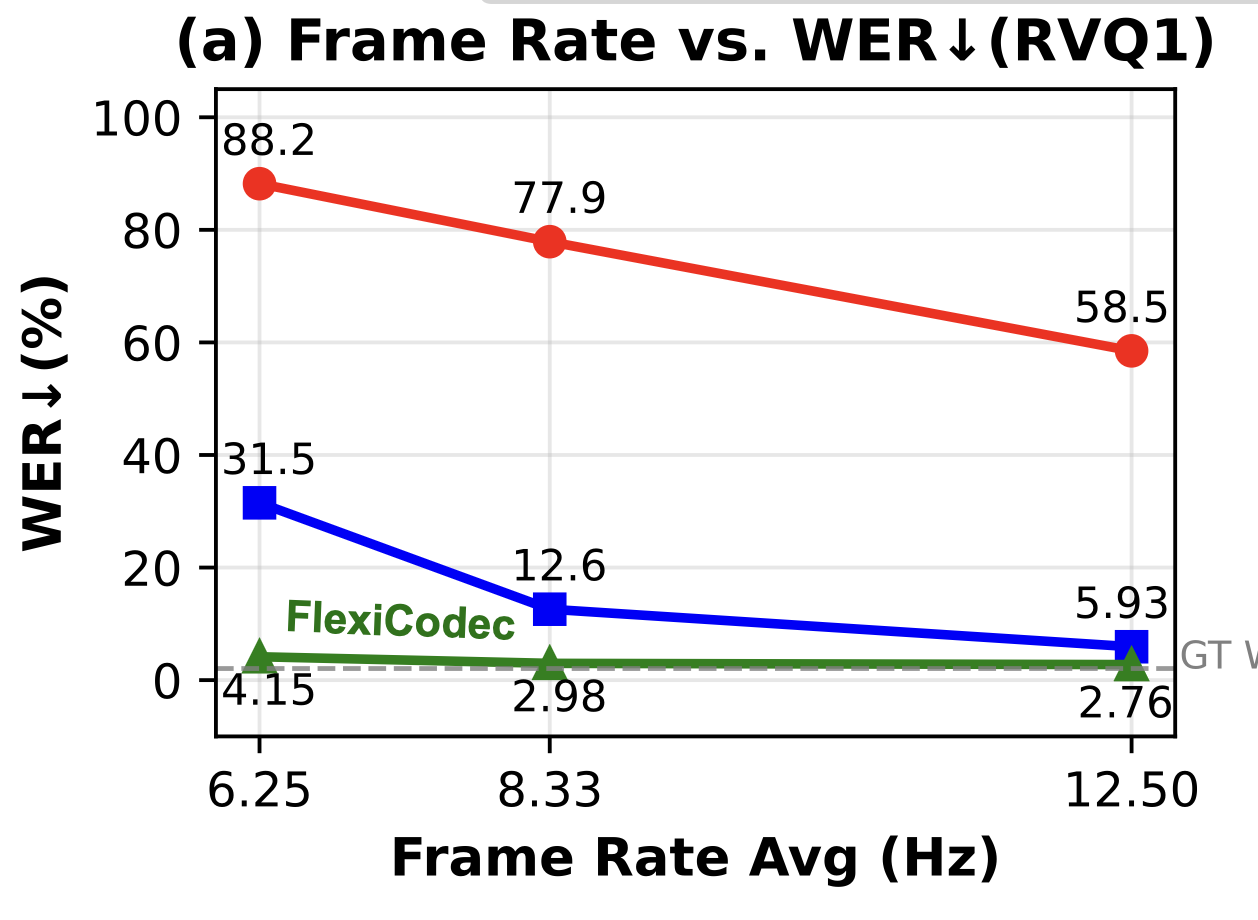
We first investigate the performance of representative audio codecs at very low frame rates. We created three new baseline versions by retraining DAC and DualCodec to operate at 12.5Hz, 8.3Hz, and 6.25Hz, respectively.
The following audios are the codec-reconstructed audios using their RVQ-1 tokens. For these RVQ-1 audios, we focus on their intelligibility instead of the acoustic details, because at such low frame rate and bitrate, it is not possible to reconstruct the acoustic details, but we can maintain the core semantic information that are useful for downstream models.
| Model | 6.25Hz (RVQ1) | 8.3Hz (RVQ1) | 12.5Hz (RVQ1) |
|---|---|---|---|
| Reference Text | if you will give us your promise to meet captain battleax here at this time to morrow we will stretch a point and delay the departure of the john bright for twenty four hours | ||
| FlexiCodec | |||
| DualCodec | |||
| DAC | |||
| GroundTruth | |||
The audios above show that FlexiCodec audios are more intelligible than other codecs especially at lower frame rates like 6.25Hz. This is confirmed by using a speech recognition to compute the WERs of the audios, as illustrated below. The rich semantic information of FlexiCodec RVQ-1 tokens is helpful for the downstream models (especially the AR models) to generate more intlligible speech.
Audio codecs can use more RVQ layers to reconstruct acoustic details. The following audios are reconstructed audios using 8 RVQ layers for each codec variant. You may not easily hear the difference, so we attach a figure of the PESQ metric.
| Model | 6.25Hz (RVQ1:8) | 8.3Hz (RVQ1:8) | 12.5Hz (RVQ1:8) |
|---|---|---|---|
| Reference Text | if you will give us your promise to meet captain battleax here at this time to morrow we will stretch a point and delay the departure of the john bright for twenty four hours | ||
| FlexiCodec | |||
| DualCodec | |||
| DAC | |||
| GroundTruth | |||
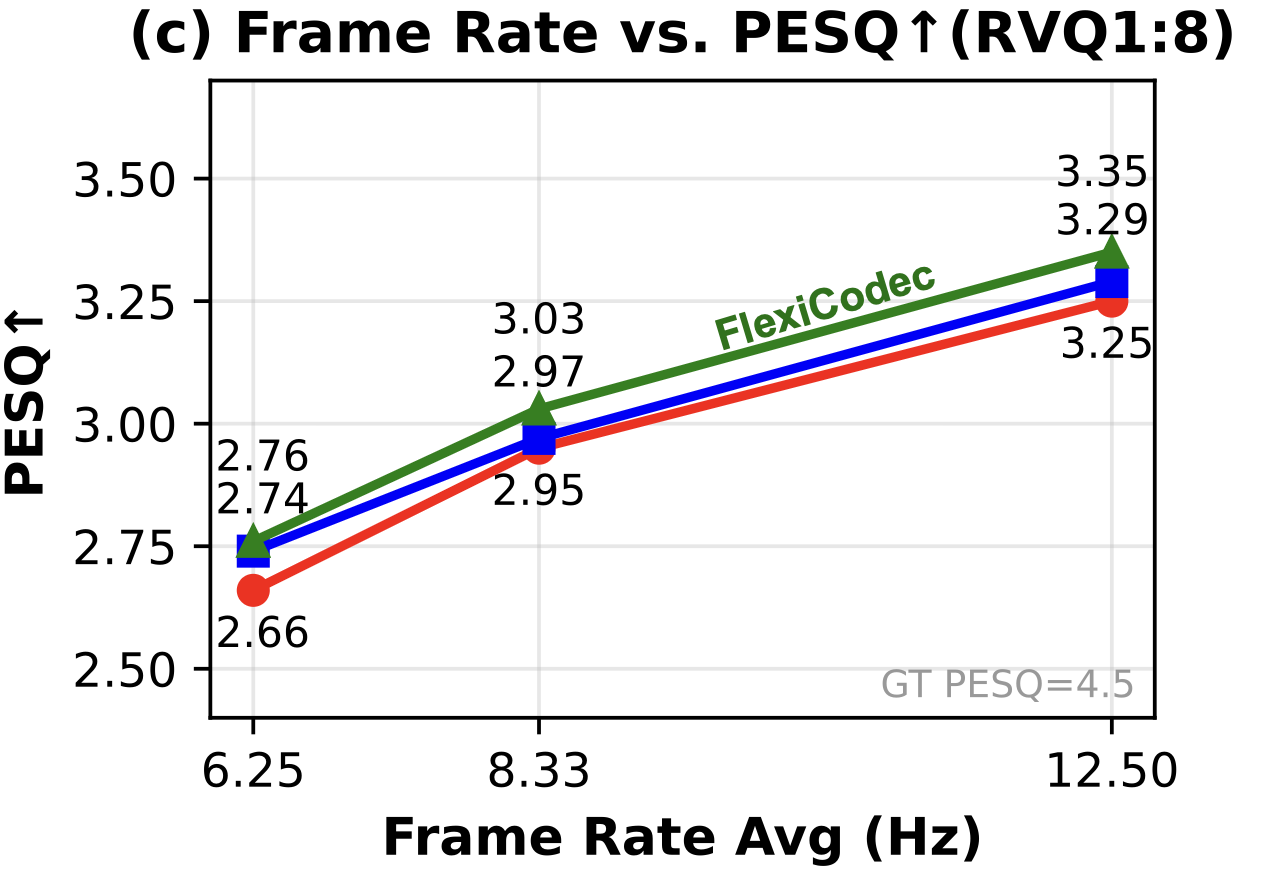
The results show that acoustic quality metrics show more moderate differences across systems and frame rates, compared to the dramatic differences in the previous semantic evaluation. We think that the acoustic fidelity is more constrained by bitrate, and because the bitrates of the three systems are at the same level, the difference is not pronounced.
The following audio comparisons showcase the quality differences between FlexiCodec and other open-source codec systems. These samples demonstrate how FlexiCodec performs compared to established codec architectures at different compression rates.
| System | RVQ1:8 | RVQ1 |
|---|---|---|
| Reference Text | if you will give us your promise to meet captain battleax here at this time to morrow we will stretch a point and delay the departure of the john bright for twenty four hours | |
| FlexiCodec@12.5Hz |
(1.3kbps) |
(0.23kbps) |
| FlexiCodec@8.3Hz |
(0.85kbps) |
(0.15kbps) |
| FlexiCodec@6.25Hz |
(0.64kbps) |
(0.11kbps) |
| GroundTruth | ||
| Encodec |
(6kbps) |
(1.5kbps) |
| Mimi |
(1.1kbps) | N/A |
| SNAC |
(0.98kbps) |
N/A |
| XCodec2 |
(0.8kbps) |
Same as left |
| XYTokenizer |
(1.0kbps) |
N/A |
| DualCodec-12.5Hz |
(1.2kbps) |
(0.19kbps) |
| SpeechTokenizer |
(4.0kbps) |
(0.5kbps) |
| TaDiCodec |
(>0.15kbps, uses additional reference audio) |
same as left |
| WavTokenizer |
(0.90kbps) |
same as left |
| System | RVQ1 BR(kbps) |
RVQ1:8 BR(kbps)/n_q |
Param | Semantic Test | Acoustic Test (RVQ1:8) | ||||
|---|---|---|---|---|---|---|---|---|---|
| WER(RVQ1)↓ | WER(RVQ1:8)↓ | PESQ↑ | UTMOS↑ | MCD↓ | SIM↑ | ||||
| > 1kbps Acoustic Bitrate | |||||||||
| DAC-75Hz | 0.75 | 6.0 / 8q | 74M | 31.2 | 2.27 | 3.77 | 3.62 | 2.34 | 0.90 |
| Encodec-75Hz | 1.50 | 6.0 / 8q | 15M | 5.90 | 2.24 | 3.12 | 3.01 | 2.60 | 0.89 |
| SpeechTokenizer-50Hz | 0.50 | 4.0 / 8q | 103M | 5.56 | 2.47 | 3.01 | 3.90 | 3.17 | 0.85 |
| Mimi-12.5Hz | - | 1.1 / 8q | 78M | - | 3.15 | 2.75 | 3.56 | 3.62 | 0.73 |
| DualCodec-12.5Hz | 0.19 | 1.2 / 8q | 84M | 5.93 | 2.26 | 3.29 | 4.18 | 2.81 | 0.85 |
| XYTokenizer-12.5Hz | - | 1.0 / 8q | 520M | - | 2.36 | 3.00 | 4.00 | 3.28 | 0.84 |
| FlexiCodec @12.5Hz | 0.23 | 1.3 / 8q | 216M | 2.76 | 2.23 | 3.35 | 4.22 | 2.76 | 0.85 |
| ∼0.8kbps Acoustic Bitrate | |||||||||
| WavTokenizer-75Hz | 0.90 | 0.90 / 1q | 81M | 4.57 | 4.57 | 2.86 | 3.98 | 3.51 | 0.68 |
| SNAC-12,23,47Hz | - | 0.98 / 3q | 20M | - | 4.21 | 2.51 | 3.43 | 3.61 | 0.67 |
| XCodec2-50Hz | 0.80 | 0.80 / 1q | 210M | 2.80 | 2.80 | 2.77 | 4.08 | 3.65 | 0.82 |
| TS3Codec(X2)-50Hz | 0.85 | 0.85 / 1q | 204M | 4.09 | 4.09 | 2.80 | 3.80 | 3.38 | 0.68 |
| FlexiCodec @8.3Hz | 0.15 | 0.85 / 8q | 216M | 2.98 | 2.28 | 3.03 | 4.21 | 3.10 | 0.78 |
| <0.7kbps Acoustic Bitrate | |||||||||
| TS3Codec(X4)-40Hz | 0.68 | 0.68 / 1q | 204M | 5.14 | 5.14 | 2.58 | 3.67 | 3.65 | 0.63 |
| TaDiCodec-6.25Hz | 0.15 | 0.15 / 1q | 751M | 4.32 | 4.32 | 1.73 | 4.05 | 9.75 | 0.83 |
| FlexiCodec @6.25Hz | 0.11 | 0.64 / 8q | 216M | 4.15 | 2.53 | 2.76 | 4.18 | 3.42 | 0.71 |
We built a text-to-speech system with FlexiCodec. This system is an AR + NAR(flow matching) TTS. The AR predicts each FlexiCodec token and its frame length using two parallel prediction heads. Because the AR model is usually the slowest part in TTS, it can greatly benefit from FlexiCodec's low frame rate. For the NAR, we tried two schemes, one is using the 50Hz male spectrogram feature, the second one is using the 12.5Hz FlexiCodec feature.
| Sample-1 | Sample-2 | Sample-3 | Sample-4 | Sample-5 | Sample-6 | Sample-7 | Sample-8 | Sample-9 | Sample-10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Reference Text | Give me a check for a hundred and fifty, and I'll turn over to you the forged check and quash further proceedings. | I have been here this quarter of an hour," replied La Valliere. | What is the tumult and rioting"? cried out the Squire, authoritatively, and he blew twice on a silver whistle which hung at his belt. | You have come to us threatening us with absolute destruction. | The sound of an imperative and uncompromising bell recalled me in due time to the regions of reality. | He was soft hearted and impetuous," said Beth; "and, being in love, he didn't stop to count the cost". | The goat's warlike spirit was roused by this successful attack. | His conduct and presence of mind in this emergence appeared conspicuous. | The Nautilus nearly perishes in the Antarctic and Nemo sinks into a growing depression. | Jack would become Eva's happy husband, and would remain amidst the hurried duties of the eager world. |
| Ground Truth | ||||||||||
| FlexiCodec-TTS (6.25Hz AR, 50Hz NAR) | ||||||||||
| FlexiCodec-TTS (8.3Hz AR, 50Hz NAR) | ||||||||||
| FlexiCodec-TTS (12.5Hz AR, 50Hz NAR) | ||||||||||
| CosyVoice | ||||||||||
| FlexiCodec-TTS (6.25Hz AR, 12.5Hz NAR) | ||||||||||
| FlexiCodec-TTS (8.3Hz AR, 12.5Hz NAR) | ||||||||||
| FlexiCodec-TTS (12.5Hz AR, 12.5Hz NAR) | ||||||||||
| SparkTTS | ||||||||||
| FireRedTTS |
Text-to-Speech demos across models. Columns are different text samples.
We find that FlexiCodec-TTS delivers strong quality at less compute than baselines. With 6.25Hz AR + 50Hz NAR, it matches or surpasses CosyVoice and SparkTTS. A 50Hz NAR consistently outperforms 12.5Hz across WER, SIM-0, NMOS, and QMOS, showing that higher temporal resolution is important for NAR. Lower AR rates (8.3/6.25Hz) preserve or slightly improve accuracy with 50Hz NAR—likely due to better semantic-acoustic disentanglement and shorter sequences that simplify attention.
This section demonstrates FlexiCodec's frame rate controllability through different merging threshold settings. The threshold parameter controls the dynamic frame rate mechanism, where lower thresholds lead to more aggressive frame merging and lower effective frame rates. As can be heard from the audios. the intelligibility is adequate at > 4.5Hz, but becomes unusable for 3.6Hz and 3.0Hz.
| Threshold / Avg frame rate | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | Sample 9 | Sample 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Reference Text | you were quite right to say no ambrose began never smoke with john jago his cigars will poison you | paul declares that the false apostles were called or sent neither by men nor by man | his hat had a peaked crown and a flat brim and around the brim was a row of tiny golden bells that tinkled when he moved | i reside in the marais rue de douze portes | the utility of consumption as an evidence of wealth is to be classed as a derivative growth | and there's linen in the house as i could well spare you for i've got lots o sheeting and table clothing and towelling as isn't made up | but i wrestled with this fellow and do know that he played unfairly in the second bout | of course he reflected she always had that combination of something homely and sensible and something utterly wild and daft | to all these inquiries the count responded in the affirmative | yes something everything said rachel hurriedly looking frowningly at a flower which she was twirling in her fingers |
| 1.00 (12.5Hz) | ||||||||||
| 0.90 (7.9Hz) | ||||||||||
| 0.80 (4.5Hz) | ||||||||||
| 0.75 (3.6Hz) | ||||||||||
| 0.70 (3.0Hz) | ||||||||||
| Ground Truth |